


Deploying HREFLANG when the global site does not want to participate
September 14, 2021GSC International Targeting Tool Depreciation
September 13, 2022Does HREFLang help with Indexing?
Earlier this week Gus Pelogia posted a very interesting question/statement on Twitter asking if Hreflang helps with indexing. He also posted the results of a test where he stated that 93% of the previously missing pages were now indexed, and a later post indicated that they continued to be indexed and driving traffic.
I had a few people ping me when they saw this question, and one client went as far as asking me why I had not made a bigger deal about hreflang helping with indexing, and another legitimately wanted to know why Gus had this positive outcome.
Does/Can Hreflang help with indexing?
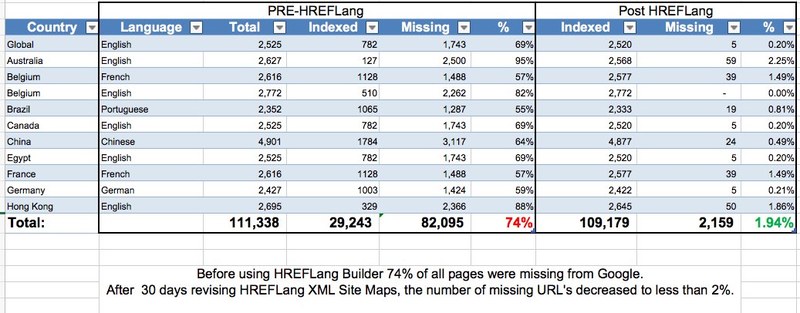
The answer is absolutely YES it can. We have a number of case studies on the site demonstrating the benefits of using hreflang to increase local market traffic and reduce cannibalization, but you can clearly see an increase in indexing. In one specific case study, the brand increased its traffic by 58%, in addition, the number of indexed URLs increased from 29k to 109k.
Why does/can hrelfang help with indexing?
The reason it can and does help with indexing is fundamental to hreflang’s purpose of what it does and the process necessary for it to work. Let’s use a simple example of an ecommerce website with four English versions of a product page that are nearly identical other than currency. Only the main site page is indexed and 3 other versions are not. The owner puts hreflang tags on the pages in heading tags.
Once the tags are added Google will come to refresh the page what was already indexed. It will encounter the hreflang tags and vapture the 3 other alternate versions. It will catalog those URLs for a visit both as part of its crawling process as well processing the hreflang directive.
A key reason I am not a fan of deploying hreflang in the head tags is that for a pair to be bound to create the original/alternate relationship, Google MUST visit the alternate page AND see the reciprocal tag back to the original URL. When this happens, there are a few key outcomes.
Reason 1 – Google becomes aware of the other page
One of the simplest benefits of indexing is that Google discovered the URL to crawl and index after capturing it from the hreflang tag. There are many reasons why Google may not have encountered the pages for the other markets. If the URLs do not get into Google’s crawl queue they will never be indexed. A very common reason is that many sites do not have links to other market websites or have a javascript country locator that only opens with a click. Some sites with IP detection or cookies may have blocked Google from entering. Note these will be a problem with hreflang tags but some IP setups allow Google to access when they request a specific market URL.
Reason 2 – Remove Canonical Selection
Given the situation above, the pages being the same language and near exact pages, Google may have been aware of the page but considered it/them to be duplicates of the original page and chose the original page as the version to show in the search results. This is VERY common for same-language pages, especially if the market/country is designated by a folder like /uk or /au. Once Google interprets the hreflang tag and determines the page serves a specific purpose of representing the product for a specific language region, it removes the canonical it set, allowing the local market page to be represented.
This is easy to see and test in the Google Search Console Coverage report by looking at the URL Inspect function for one of the missing pages before and after hrelang implementation.
{kind=link}