The first step of developing and deploying HREFLang Elements for your site is understanding and gathering your source files. The purpose of this article is to outline some of the challenges we see with building the lists of URL’s and suggestions for overcoming them.
Challenge 1 – XML Site Maps
We have encountered a number of problems with using XML site maps for the main source. You would assume that output from your own system would be the best and most complete listing of all of the live URL’s on your site. That is not always the case and we are finding that they can be anywhere from 10 to 90% variation from the actual available URL’s. That is why we created our Page Alignment Tool to allow us to upload data and find these sorts of anomalies.
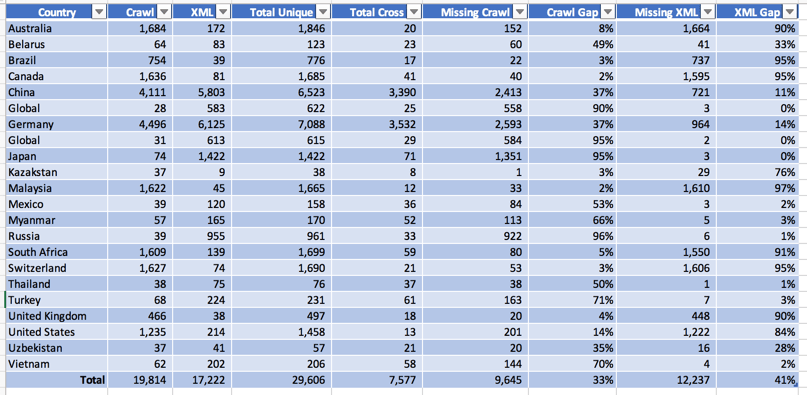
This screen capture illustrates this problem. In this case, the CMS created XML site maps for the countries with a total of just over 17k pages. We compared it to a crawl of the sites by the SEO team and that turned up nearly 20k pages which were closer to the number the client expected. What was interesting is when we merged them we found a total of nearly 30k unique URL’s with only 7.5k to be the same on both lists. This means both of the source files had problems.
In the case of Malaysia, 97% and on average 41% of the pages were missing from the XML site maps. For this site, the crawl was also incorrect. In the case of Russia, the crawl missed 96% of the URL’s that were on the XML site maps.
The following are some of the most common reasons for these variations and other challenges with using XML site maps as your source.
What is included
It is actually very rare that anyone can tell us the rules for what is included in their XML site maps. Sometimes PDF or content behind selectors or even some subdirectories are blocked from the internal systems. You need to review with the CMS team what they have set to be included in the XML site map and ensure that the critical items are included.
Not Localized
There are a few of the larger CMS systems that are integrated with localization tools and they are purposely set to not add a page for a market to the XML site map if it is not been localized. If the plan is to deploy the page with partial localization or in English the system may not let you add it until it has been through the final localization review process.
Localized Page Names
There are a few CMS tools that need the page name to match in order to keep them synchronized. Sometimes a local marketing manager will want to have a localized version of a page name and change it. If the “page alias” has not been set up in the CMS there is no way to map them to each other and they might be identified as an orphan page and left off the list. Adobe AEM Localized Page Alias has this fairly well documented and you might use their guide to help you find how your CMS handles localized URL’s.
Not Selected
Some CMS systems require the user to actively add the localized page to the system. If you find specific pages have not been added you should check to make sure the localization team has clicked the option to add the newly localized page to the XML site map and into production. We have found entire sections of websites that were not listed on site maps due to the localizer for that content not knowing they needed to take this step.
Global Page All Markets
Some systems like EpiServer have a default solution that if you don’t localize the page it will use the global, typically English version of the page, this page is shown as a local English version when requested by a user or search engine, but is not typically added to the XML site map.
Error Checking
There are some systems that are really smart and use the Robots.txt or other directives to exclude pages. We have found cases where a local market has a block on the robots.txt file during the development of the local version and that was never removed when it went live. The CMS respected that block and would not push the pages live. This can also happen when pages are cloned from one version to another and the canonical tag is not updated to the correct version for the page.
Lack of Error Checking
While some systems are really smart and never let a “bad URL” get added to the system there are those that don’t do any checking at all and lots of bad URLs can be added. We had a case recently where over 3 million error URLs were added to the XML site maps rendering them useless causing Search Engines to completely ignore them.
Challenge 2 – Crawler Tools
Crawling tools like DeepCrawl, Botify, and Screaming Frog all emulate a Search Engine’s crawler. For HREFLang Builder we only need a list of validated URLs and not all of the other elements that these tools typically capture and return. We like to integrate the URL’s from these tools to augment XML site maps. As noted above, there was actually very little overlap between the two sources, and by having them both integrated we are able to get the most complete set of URLs.
Crawl Limits Due to Budget
Enterprise crawling tools are becoming quite expensive as they become more complex in what they are gathering. Especially now with people wanting to emulate a browser view and capture all the content the cost to crawl and store it is increasing. Sure for SEO diagnostics you only need a sampling of pages to find problems. This is often why a site with 50 million pages has an account with a limit of 50,000 unique requests.
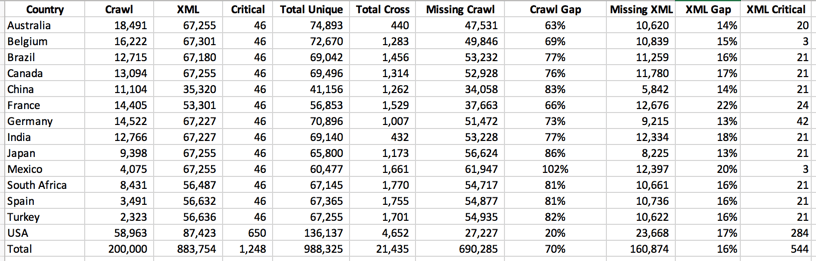
In the screen capture above, you can see the client has a cap of 200k urls in their Botify subscription. It tried to crawl the majority in the US where it started and you can see a steady decline as it goes across the various markets. As it jumped into Australia and Belgium it got more URL’s than Spain and Turkey which were farther down on the country/language selector. The client was limited to a max of URL’s that could be crawled. Again in this model, we see that of nearly 1 million unique URLs the two source files only had 21k URL’s in common. This makes us believe that both sources of URL’s are not complete.
A relatively inexpensive way around expensive tools is to use Screaming Frog and use their scheduler function to set up jobs to run for each of the countries. We have clients with over 100 sites using this method. They
set up Screaming Frog to weed out any problem URL’s and the scheduler crawls each of the sites and saves the XML file to Dropbox where we can
import source files from Dropbox dynamically. With a Screaming Frog and Dropbox license, this is a $300 annual cost and no incremental cost if you have these already just the sweat equity required to set it up.
SEO Tool Crawl Limits
Beyond the account limits, many sites also put crawl limits on the tools. It is critical now that you whitelist the crawler’s IP’s and not set any restrictions other than the number of requests per minute. We have encountered problems where some countries were blocked from various tools and did not let them access to do any of the tests.
Selectors/AJAX and JavaScript
Just as many spiders have problems getting into product selectors of pages build with JavaScript and AJAX these tools can have those same problems. The client in the case above increased their crawl limit to 1 million pages for the test. In doing so they increased the number of pages found by nearly 500k. But they were exactly 200k off from the XML site map. Again researched the gap and found that there were nearly 20k tech specs/research documents behind a product selector that the spider could not get by but could be added to the XML site map.
Challenge 3 – PLP/Critical Page Inclusion
We pioneered the idea of Preferred Landing Pages as a way to measure if the desired page was the page actually ranking. Most of the mainstream tools do not have this same type of setting. In both of the screen captures you can see that a significant number of the critical pages they have set were not included in the XML files. This is why we added the ability to append URL’s to the XML site map. You should check to make sure that all of the pages you are monitoring for rank, especially for mission-critical phrases are actually added to the XML site maps and most importantly indexed.